



Following the completion of all training and testing phases with success, the proposed denoising model demonstrated impressive efficacy in removing noise (Artifacts) from EEG signals while preserving essential brain signal data.
The proposed model underwent rigorous optimization using 80% of the dataset during the training stage. The trend of decreasing loss values over time indicates that the model demonstrated consistent convergence. This implies that during the training stage, the model successfully learned to denoise EEG signals.
Utilizing the remaining 20% of the dataset in the testing phase, the model exhibited robust performance. After that the quantitative assessment was performed using metrics such as Normalized Mean Squared Error-NMSE, Root Mean Squared Error-RMSE, Correlation Coefficient-CC, Signal to Noise Ratio-SNR and Signal to Artifact Ratio-SAR. These metrics provided a comprehensive evaluation of how closely the generated signals matched the original EEG signals, reflecting a strong agreement between them.
In Fig. 4, segments of each artifact (eye blink, eye-movement, chewing, clench teeth) are presented. The figure exhibits the raw EEG signals alongside those generated by the proposed model and signals cleaned using wavelet decomposition methods.
Distinct characteristics of each artifact are observable: eye blink artifacts are denoted by high sudden spikes in the EEG signals, while eye-movement artifacts display square waves. Chewing artifacts appear as rhythmic and repeated patterns with moderate to high amplitude, and clenching teeth artifacts are typified by high-amplitude spikes.
The raw EEG signal are represented by the green signal, while the signals highlighted in red and blue depict the corrected signals after artifact removal. These denoised signals demonstrating how well the method works to reduce artifacts while preserving the integrity of the EEG data. In smoother waveforms, The removal of artifacts results, facilitating more accurate analysis of underlying brain activity. After denoising, the red signal successfully reduces the abrupt oscillations found in the green signal, as can be seen by comparing the two signals. The comparison clearly illustrates how the proposed method effectively reduces artifacts while maintaining the integrity of the underlying EEG data. The denoised signals provide strong evidence of the model’s capability to preserve essential brain activity while minimizing unwanted noise, thus ensuring a cleaner and more accurate representation of the EEG signals.

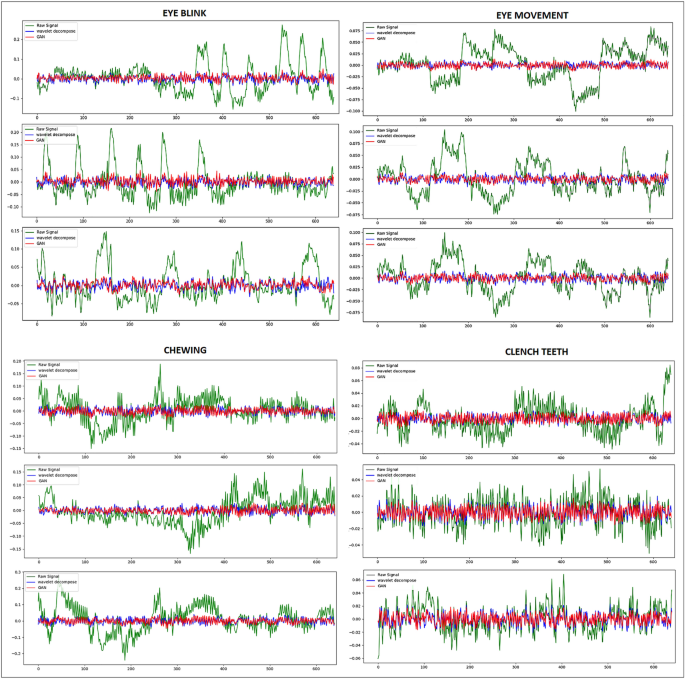
Raw EEG signals (Green), Wavelet Denoised EEG signals (Blue) and generated signal by the proposed model (Red) of Eye Blink and eye-movement, Chewing and Clench Teeth artifacts.
In Fig. 5, an EEG signal displaying both the presence of Eye Blink artifact and its clean counterpart across 32 channels is showcased. The clean EEG signal is represented by the green signals, while the artifact affected EEG signal is depicted in orange. This visualization provides a clear comparison between the noisy and clean signals. Additionally, the successful removal of other artifacts, such as eye-movement, chewing, and teeth clenching, from the EEG signals has been documented and made available for review. These results, along with the corresponding EEG images, have been uploaded to the GitHub repository, as referenced in34. This allows for further examination and validation of the model’s performance across various types of artifact.

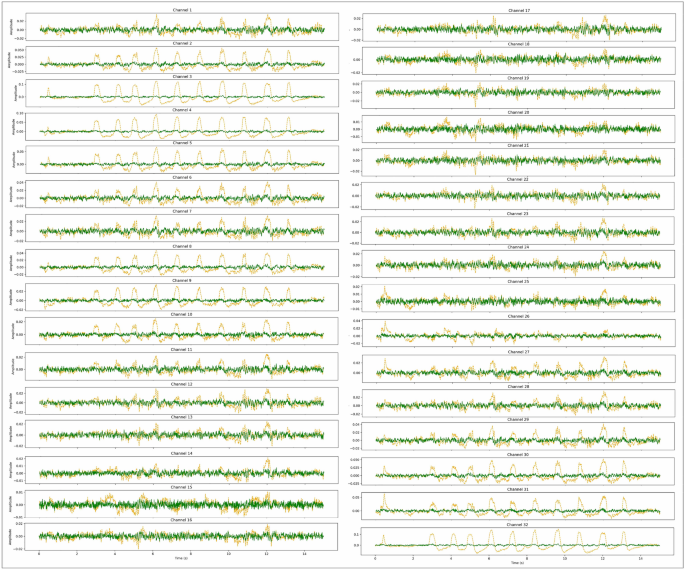
Eye Blink Artifact (Orange) vs. Clean Signal (Green) Across 32 Channels.
Following the quantitative analysis, which included assessing NMSE, RMSE, CC, SNR and SAR, the generated signals were compared with the original signals, as well as the signals cleaned by wavelet decomposition methods with the original signals. Subsequently, both the GAN-based signals and the wavelet-based signals were compared to determine which performed better.
For examining the characteristics of the signals, RMSE was used, which gives information about the average magnitude of the errors between the generated or wavelet-decomposed signals and the original signals. By focusing on the deviations in signal reconstruction, RMSE helps quantify how closely the denoised signals resemble the true, artifact-free signals.
In Table 3, the RMSE value for each electrode was calculated, comparing the original signal with the wavelet-based signal and the original signal with the signal generated by the model. The RMSE values for the generated signals are consistently smaller than wavelet denoising signals for most electrodes, there are exceptions observed, indicating the superior performance of the proposed model in preserving the integrity of the EEG signals. The average RMSE for the generated eye blink, eye-movement, chewing, and clench teeth signals is 0.0739, 0.0336, 0.0609, and 0.0345 respectively, while the average RMSE for the wavelet-based signal is 0.0753, 0.0353, 0.0621 and 0.0355 respectively. It means that the proposed model-generated signal generally showed more effective agreement with the original signals compared to the wavelet-based signals. Lower RMSE (Root-mean-square Error) values indicate better agreement between the original (Raw Signal) and reconstructed signal. Therefore, in conclusion, the signals generated by the proposed model possess more accurate characteristics compared to those obtained through wavelet methods, although some electrodes may require further investigation.
After assessing the RMSE values, the similarity between the original and noise-free signals using NMSE was evaluated. By calculating NMSE, the model’s ability to accurately reconstruct the clean signal from the noisy input is assessed.
For NMSE, the original signal and the wavelet denoised signal as well as the NMSE value between the original signal and the reconstructed signal were computed. It can be observed that the NMSE values of the generated signals are close to zero relative to the wavelet-denoised signals. Table 4 presents all the calculated NMSE values. For all 32 electrodes, the NMSE values were calculated and averaged, it was found that the average NMSE value for the generated signal by the proposed model for eye blink, eye-movement, chewing, and clench teeth is 0.0320, 0.0195, 0.0131, and 0.0089 respectively, while the average NMSE value for the wavelet-based signals is 0.0388, 0.0257, 0.0175 and 0.0124 respectively. This indicates that the proposed model created signal are more similar to the original signal compared to the wavelet-based denoised signals. NMSE values close to zero imply a good match between the original and reconstructed signal, while the higher values of NMSE signify greater discrepancies between the original and reconstructed signal.
These results demonstrates that, in terms of maintaining the similarity between the generated and original noise-free signals, the proposed model performed better than the wavelet-based methods, as seen by the generated signals’ lower average NMSE values.
After the NMSE evaluation, the model was assessed based on the likeness between the original and denoised signals by calculating the correlation coefficient (CC). CC was calculated both between the original signal and the reconstructed signal, as well as between the original signal and the wavelet-denoised signal. All calculated values for the 32 channels are shown in Table 5. The average CC for the generated signal is 0.6985, 0.6440, 0.6244, and 0.61 for eye blink, eye-movement, chewing, and clenching teeth signals, respectively, indicating a strong linear agreement with the original signals. In contrast, the average CC for the wavelet-based signals was 0.6280, 0.5638, 0.5686, and 0.5685 respectively.
A higher CC value indicates a more robust linear relationship between the original and reconstructed signal. In contrast to the wavelet-based denoised signals, the higher average CC value found for the created signals indicates a tighter alignment with the original signal. This indicates the strength of the model, in maintaining the linear relationship between the original and generated signal, confirming its efficiency over the wavelet-based method.
To evaluate the effectiveness of the proposed model, Signal-to-Noise Ratio-SNR was also evaluated. SNR measures the strength of the signal relative to the level of noise, making it an essential indicator of how well the noise has been subtracted and how much the signal power has been enhanced in the generated signals by the proposed model. The SNR across all 32 electrodes for all artifacts: Eye Blink, eye-movement, Chewing, and Clench Teeth was calculated. The signals were divided into four frequency bands: Theta (4–8 Hz), Alpha (8–13 Hz), Beta (13–30 Hz), and Gamma (30–50 Hz).
For the Eye Blink artifact(refer Table 6), the proposed model demonstrated superior performance with average SNR values of 7.71, 10.62, 13.08, and 10.42 for the Theta, Alpha, Beta, and Gamma bands, respectively. In comparison, the raw artifacted signal yielded lower SNR values of 3.24, 3.91, 2.23, and \(-\)2.95. The wavelet-based (DWT) denoised signal showed improvements with SNR values of 6.72, 10.26, 10.62, and 10.63.
For the eye-movement artifact (refer Table 7), the proposed model again outperformed the raw and DWT-cleaned signals. The generated signal achieved average SNR values of 7.10, 6.64, 13.54, and 13.57 across the Theta, Alpha, Beta, and Gamma bands, respectively. In contrast, the raw artifacted signal had much lower SNR values of 3.61, \(-\)0.44, 2.69, and 0.54, while the DWT-cleaned signal reached 6.20, 5.94, 12.25, and 12.98.
For the Chewing artifact (refer Table 8), the proposed model consistently outperformed both the raw and DWT methods. The average SNR values for the generated signal were 5.51, 6.48, 12.60, and 14.73 in the Theta, Alpha, Beta, and Gamma bands, respectively. The raw artifacted signal had lower SNR values of 3.16, 0.59, 5.37, and 5.50, while the DWT-cleaned signal yielded 3.09, 5.05, 11.69, and 14.37.
Lastly, for the Clench Teeth artifact (refer Table 9), the proposed model showed superior performance with SNR values of 5.51, 7.27, 13.01, and 14.55 in the Theta, Alpha, Beta, and Gamma bands, respectively. The raw artifacted signal exhibited SNR values of 5.09, 3.61, 7.08, and 5.73, while the DWT method resulted in 3.64, 6.61, 12.16, and 13.77.
Overall, the results demonstrate that the proposed model consistently achieves higher SNR values across all frequency bands compared to both the raw and DWT-cleaned signals. There is a general trend where the SNR increases with frequency, indicating that the signal quality improves relative to the noise as frequency increases. This suggests that the higher frequency components of the signal are more distinct and less affected by noise in the proposed model compared to the DWT approach. All the values are plotted separately for each artifact for better comparison: the Eye Blink plot is shown in Fig. 6A, the eye-movement plot in Fig. 6B, the Chewing plot in Fig. 6C, and the Clench Teeth plot in Fig. 6D. In these plots, the orange represents the GAN-based signal, the grey represents the DWT-based signal, and the blue represents the raw signal.

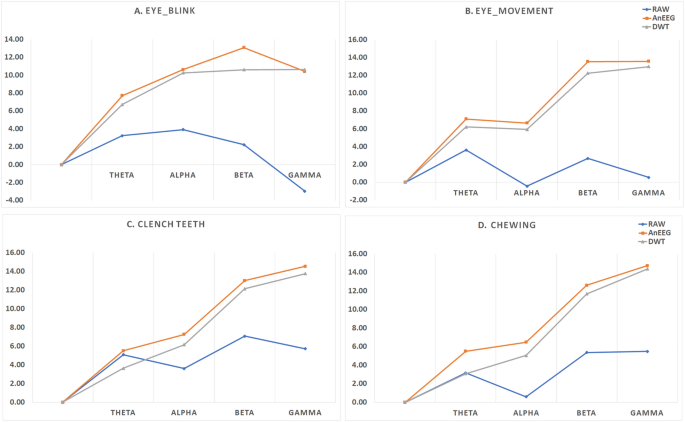
Comparative SNR Analysis Across Frequency Bands for (A) Eye Blink, (B) Eye-movement, (C) Chewing, (D) Clench Teeth Using the Proposed Method—AnEEG (Orange), DWT based Method (Grey), and Raw Signals (Blue).
After evaluating the Signal-to-Noise Ratio (SNR), we also calculate the Signal-to-Artifact Ratio (SAR) for each artifact. SAR is another important metric that quantifies the ratio between the clean signal and the residual artifact.SAR was calculated for all 32 electrodes across all four artifacts: Eye Blink, Eye-movement, Chewing, and Clench Teeth. Afterward, the SAR values were averaged across all channels to obtain an overall performance measure. The evaluated data is presented in Table 10, showcasing the model’s ability to reduce artifacts.
The average SAR value for Eye Blink is \(\textbf 0.\textbf 87\) for the GAN-based method, compared to 0.83 for the DWT-based method. For Eye-movement, the GAN approach achieved a SAR of \(\textbf 0.\textbf 62\), while DWT achieved 0.50. In the case of Chewing artifacts, the GAN method resulted in a SAR of \(\textbf 0.\textbf 90\), while DWT yielded 0.80. Lastly, for Clench Teeth artifacts, the GAN method outperformed DWT with a SAR of \(\textbf 1.\textbf 47\) compared to 1.38. In all artifact, the proposed method demonstrated superior performance in artifact removal compared to DWT.
After testing and evaluating all the criteria on the split artifact dataset, the model was also analysed on an additional dataset, “SAM-40”36 which was recorded at Gauhati University, Department of Information Technology, Guwahati, Assam , India. This dataset was gathered from 40 subjects to monitor induced stress while performing tasks such as the Stroop color-word test, arithmetic tasks, and mirror image recognition tasks.
The same pre-processing technique was used on this dataset like the proposed dataset. Then, taking one subject’s data to clean artifact, and then analyzed the RMSE, NMSE, CC, SNR, and SAR for the clean signals generated by the proposed model. The RMSE, NMSE, and CC values were calculated for all 32 electrodes and then averaged. These values are described in Table 11. Additionally, SNR and SAR values are presented in Table 12.
In the SAM-40 dataset, the RMSE for the proposed model’s generated signal is 0.0819, compared to 0.0831 for DWT. The NMSE for the generated signal is 0.0066, while DWT’s NMSE is 0.0164. The CC for the proposed model’s generated signal is 0.5894, compared to 0.5273 for DWT. These results indicate that, once again, the proposed model outperforms DWT, with lower RMSE and NMSE values, and a higher CC value.
The SNR and SAR values are preseneted in Table 11, the SNR was calculated across different frequency bands. The SNR for the proposed model’s generated signal is 6.95 in the Theta band, 9.72 in the Alpha band, 13.44 in the Beta band, and 12.62 in the Gamma band. In comparison, the SNR for the raw artifacted signal is 2.32 in Theta, 2.90 in Alpha, 4.33 in Beta, and 0.63 in Gamma. For the DWT-cleaned signal, the SNR is 5.31 in Theta, 8.62 in Alpha, 11.79 in Beta, and 11.43 in Gamma. A general trend where SNR rises with frequency was noted, suggesting that the signal quality improves relative to noise as frequency increases. The graph illustrating these SNR comparisons is plotted in Fig. 7, where orange represents the proposed model’s generated signal, grey represents DWT, and blue represents the raw signal.

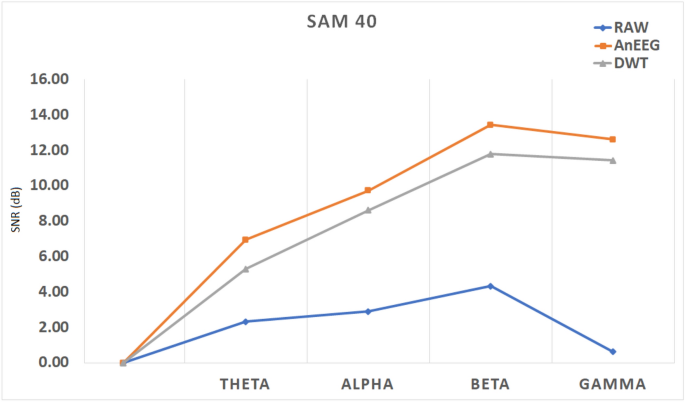
Comparative SNR Analysis Across Frequency Bands for “SAM-40” Dataset Using the Proposed Method (AnEEG) (Orange), DWT based Method (Grey), and Raw Signals (Blue).
Lastly,the SAR for the SAM-40 dataset was calculated. The SAR values are also described in Table 11 alongside SNR. The SAR for the proposed model is 1.34, compared to 1.09 for DWT. This further demonstrates the proposed model’s superior performance in artifact removal and signal preservation.
Hence, the proposed GAN-based denoising model showed remarkable effectiveness in eliminating noise from EEG signal, while keeping the crucial information about brain activity. Quantitative indicators like NMSE, RMSE, and CC show that the model consistently performed well throughout the demanding training and testing process.
link