



Selection and construction of the BPNN model
BPNN
Basic principles of BPNN: The BPNN is a multilayer feedforward neural network trained using the backpropagation algorithm. It is widely used in fields such as pattern recognition, classification, and regression23.
The basic structure of the BPNN includes an input layer, hidden layers, and an output layer, with weights connecting each layer. During training, the network first performs a forward pass of input data to calculate the output. Then, based on the output error, it adjusts the weights in a backward direction, gradually minimizing the error until it meets a predefined convergence condition24. The core of the BPNN lies in its backpropagation algorithm, which updates weights using the gradient descent method. The specific steps are as follows:
First is forward propagation, where input data flows from the input layer to the output layer. The output of each neuron in a layer is calculated by taking a weighted sum of the previous layer’s outputs and applying an activation function. Letting \(z_{j}^{l}\) represent the input and \(a_{j}^{l}\) the output of neuron j in layer l, Eqs. (1) and (2) are obtained:
$$z_{j}^{l} = \sum\limits_{{{\text{i}} = 1}}^{{n^{l – 1} }} {w_{ij}^{{\text{l}}} } a_{i}^{l – 1} + b_{j}^{l}$$
(1)
$$a_{j}^{l} = f\left( {z_{j}^{l} } \right)$$
(2)
\(w_{{ij}}^{{\text{l}}}\) is the weight between the i-th neuron of layer l − 1 and the j-th neuron of layer l, \(b_{j}^{l}\) is the bias of the j-th neuron in layer l, and \(f(\cdot )\) is the activation function.
Second is the error calculation, which involves computing the error based on the difference between the predicted values from the output layer and the actual values. Let the network output be \({a^L}\), and the true value be y. The error E is calculated as shown in Eq. (3):
$$E = \frac{1}{2}\sum\limits_{j = 1}^{{n^{L} }} {\left( {y_{j} – a_{j}^{L} } \right)^{2} }$$
(3)
\({n^L}\) is the number of neurons in the output layer, \({y_j}\) is the true value of the j-th output, and \(a_{j}^{L}\) is the predicted value of the j-th output.
Third is backpropagation, which starts from the output layer and works backward, computing the error term for each neuron in each layer and adjusting the weights based on the error term. The error term \(\delta _{j}^{{l}}\) for the j-th neuron in layer l is computed as shown in Eq. (4):
$$\delta_{j}^{L} = \left( {a_{j}^{L} – y_{j} } \right)f^{\prime } \left( {z_{j}^{L} } \right)$$
(4)
\(f^{\prime } (z_{j}^{L})\) is the derivative of the activation function f at \(z_{j}^{L}\).
$$\delta_{j}^{l} = f^{\prime } \left( {z_{j}^{l} } \right)\sum\limits_{k = 1}^{{n^{l + 1} }} {w_{{j^{k} }}^{l + 1} } \delta_{k}^{l + 1}$$
(5)
\({n^{l+1}}\) is the number of neurons in layer l + 1, \(w_{{{j^k}}}^{{l+1}}\) is the weight between the j-th neuron in layer l and the k-th neuron in layer l + 1, and \(\delta _{k}^{{l+1}}\) is the error term of the k-th neuron in layer l + 1.
Fourth is weight update. The gradient descent method is used to update the weights, minimizing the total error of the network. The weight and bias updates are shown in Eq. (6):
$$w_{ij}^{l} \leftarrow w_{ij}^{l} – \eta \delta_{j}^{l} a_{i}^{l – 1}$$
(6)
\(\eta\) is the learning rate, which controls the speed of weight updates.
In this study, the structure of the BPNN is shown in Fig. 1.

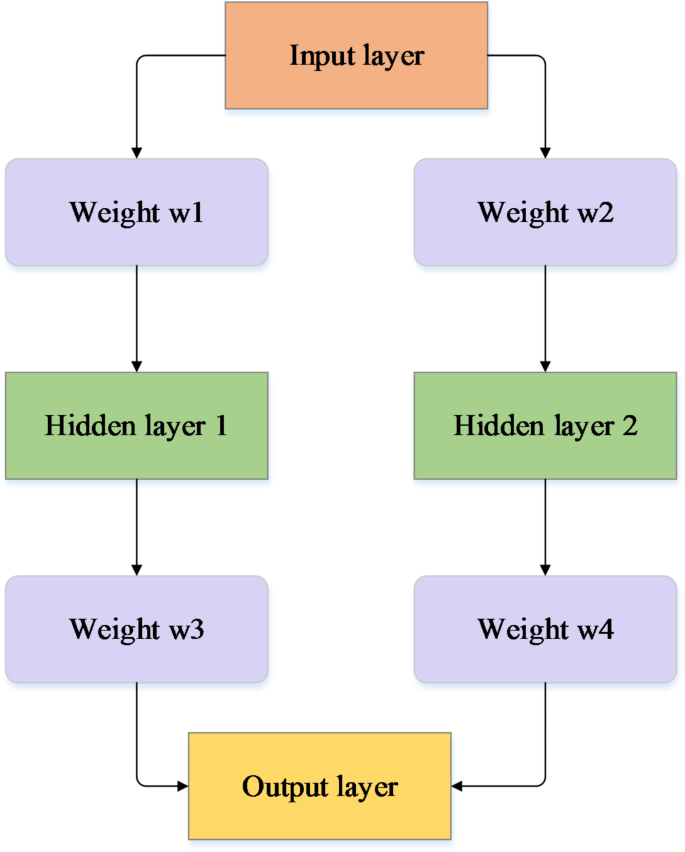
In Fig. 1, the specific application of the BPNN is as follows:
First, the input layer is designed to include multiple features related to student performance and engagement, such as academic achievements, participation in practical activities, and internship feedback. These features are selected based on their potential to influence student outcomes and are normalized to ensure consistency in the input layer.
Second, the BPNN utilizes a dual-path architecture with two hidden layers to handle the complexity of predicting educational outcomes. This configuration enables the model to capture both linear and nonlinear relationships in the data, enhancing its ability to learn and generalize patterns observed in student data. The two hidden layers provide additional capacity for processing the complex interactions between input features, which is crucial for accurately modeling the multifaceted nature of student performance.
Third, the weight initialization and optimization process (w1–w4) in this study is crucial to the model’s performance. Weights are initialized using a random normal distribution to break symmetry and encourage diverse feature learning during the early stages of training. The optimization process employs the Adam algorithm, which adapts the learning rate for each parameter based on the gradient’s size, facilitating faster convergence and more efficient training within the network.
Fourth, the size of the hidden layers is determined through a series of hyperparameter tuning experiments. The first hidden layer contains 128 nodes, and the second hidden layer contains 64 nodes. This configuration strikes a balance between the model’s ability to learn complex patterns and the risk of overfitting. The number of nodes in each layer is chosen to ensure the model has sufficient representational capacity while maintaining its ability to generalize to new data. In the context of educational applications, this balance is essential for achieving high predictive accuracy and robustness.
Selection and construction of the BPNN model
In this study, the BPNN was chosen as the core model for its ability to efficiently process data and deliver high levels of prediction accuracy. To enhance both the model’s performance and its stability, multiple critical aspects were considered throughout the model’s design and implementation stages.
Firstly, the network structure was carefully designed, comprising an input layer, hidden layers, and an output layer. The number of nodes in the input layer was set according to the number of input features, while the output layer nodes corresponded to the number of target outputs. The configuration of hidden layers, including the number of layers and nodes in each layer, was optimized through experimentation. Generally, adding more hidden layers or nodes can increase the model’s representational power, though it may also introduce a risk of overfitting if not carefully managed. Fine-tuning this balance is essential for achieving optimal model performance.
Secondly, the selection of the activation function significantly influences the model’s accuracy and computational efficiency. Common activation functions such as Sigmoid, ReLU, and Tanh each have distinct characteristics. For this study, ReLU was employed in the hidden layers due to its ability to prevent the vanishing gradient problem and improve convergence speed. For the output layer, different activation functions were selected based on the task requirements: Softmax was applied for classification, while a linear activation function was used for regression tasks. This task-specific choice of activation functions helps to ensure the network is well-suited for the problem at hand and can yield reliable predictions25.
Thirdly, the loss function, which quantifies the error between predicted and actual values, is another pivotal component of the BPNN. The choice of loss function directly impacts how the model learns during training. In this study, mean squared error (MSE) was chosen as the loss function due to its suitability for regression-based tasks, as outlined in Eq. (7). MSE effectively penalizes larger errors more heavily, which aids in the accurate refinement of model parameters to minimize prediction errors. Other potential loss functions, such as cross-entropy for classification tasks, were considered based on the task type but ultimately not selected in this regression-focused context26.
By carefully addressing each of these factors—network structure, activation function, and loss function—the BPNN model was designed to provide robust and stable performance, ensuring it meets the study’s objectives effectively. This thorough configuration of the model’s architecture strengthens its capacity to generalize well on unseen data and reinforces its utility in educational applications where accurate predictions and responsive feedback are critical.
$$E = \frac{1}{2}\sum\limits_{j = 1}^{{n^{L} }} {\left( {y_{j} – a_{j}^{L} } \right)^{2} }$$
(7)
E is the total error, \({y_j}\) is the true value of the j-th output, \(a_{j}^{L}\) is the predicted value of the j-th output, and \({n^L}\) is the number of neurons in the output layer.
The fourth key factor is the optimization algorithm, which is used to update the network weights27,28. Common optimization algorithms include gradient descent, momentum, and Adam. In this study, the Adam optimization algorithm is selected due to its combination of the benefits of momentum and RMSprop, enabling faster convergence while minimizing the risk of getting stuck in local optima.
Specific implementation methods of the industry–education integration model
-
(1)
Intelligent course recommendation system.
The intelligent course recommendation system is an essential part of the industry–education integration model based on BPNN. This system analyzes multidimensional data, such as students’ learning history, interest preferences, and performance records, to provide personalized course recommendations for each student.
-
(2)
Employment guidance services.
Employment guidance services are a key component of the BPNN-based industry–education integration model, aimed at helping students better plan their career paths and improve their competitiveness in the job market. The specific implementation steps are as follows:
First, data preprocessing is performed by collecting students’ learning history data, including course selection records, grades, learning behaviors, etc. The data is then cleaned and standardized to ensure quality and consistency. Second, feature extraction involves extracting useful features from the preprocessed data, such as students’ learning interests, learning abilities, and course difficulties. This process is carried out using statistical analysis and machine learning methods. Third, model training is conducted using BPNN to train the extracted features and construct the course recommendation model. The model’s input is the student’s feature vector, and the output is the probability distribution of recommended courses. During training, mean squared error is used as the loss function, and the Adam optimization algorithm is applied for weight updates. Fourth, service provision involves offering students personalized career planning advice and job search guidance based on the model’s output. The advice and guidance include career directions, skill training, interview techniques, etc. Fifth, effect evaluation is carried out through user surveys and experimental data to assess the effectiveness of the employment guidance services. Key indicators include student employment rates, job satisfaction, and career development.
-
(3)
School-enterprise cooperation mechanism.
The school-enterprise cooperation mechanism is a core element of the industry–education integration model29, aiming to promote deep communication and cooperation between universities and enterprises, achieving resource sharing and complementary advantages. The specific implementation steps are as follows:
First, platform construction involves establishing a web-based school-enterprise cooperation platform that provides functions such as information release, project management, and resource matching. The platform uses a modular design for easy expansion and maintenance. Second, project cooperation encourages enterprises to play an active role in course design, training base construction, and teacher training, ensuring that the teaching content aligns closely with industry demands. Enterprises can use the platform to post project requirements and invite university staff and students to participate in real-world projects. Third, resource matching is implemented through the platform, facilitating resource connections between universities and enterprises, such as experimental equipment, training bases, and research projects. Resource matching helps improve teaching quality and students’ practical abilities. Fourth, effect evaluation is conducted through experimental data and user feedback to assess the effectiveness of the school-enterprise cooperation mechanism. Key indicators include project completion quality, students’ practical skills, and enterprise satisfaction.
The flowchart of the BPNN-based industry–education integration model is shown in Fig. 2.

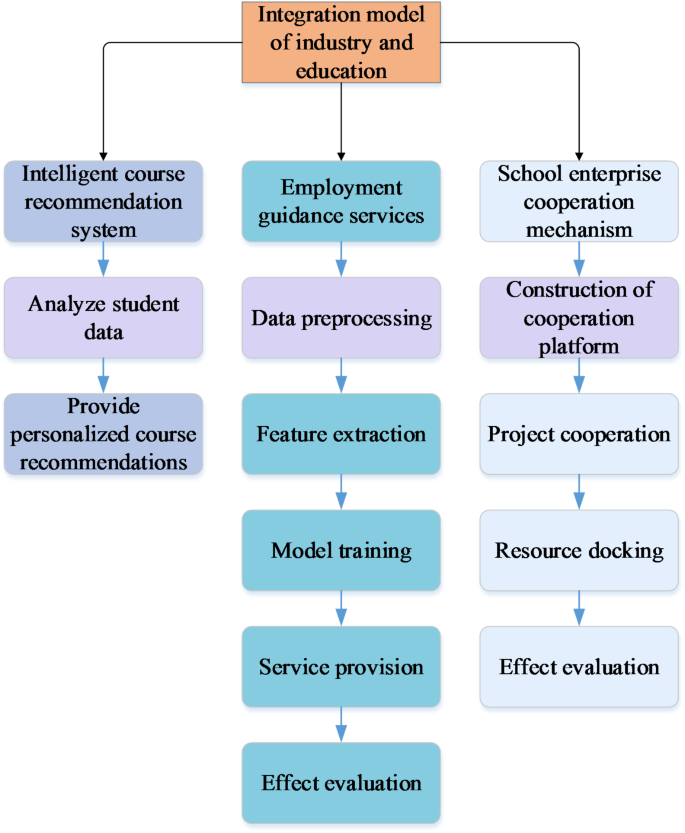
BPNN-based industry–education integration model flow.
Figure 2 illustrates the logical framework of the BPNN-based industry–education integration model. First, the specific implementation of BPNN in each component is as follows. In the intelligent course recommendation system, the BPNN analyzes multidimensional data such as students’ academic performance, interest preferences, and past course records to provide personalized course suggestions. In the career guidance service, the BPNN uses students’ learning history and abilities to offer career planning advice and an analysis of their competitiveness in the job market. In the school-enterprise cooperation mechanism, the BPNN helps match enterprise needs with student capabilities, fostering project collaboration and resource sharing. The preprocessing methods for different types of input data include data cleaning, feature extraction, and normalization. Data cleaning aims to remove missing and outlier values, ensuring the quality and consistency of the data. Feature extraction involves extracting key information from the raw data that contributes to model training, such as students’ learning habits, grade trends, and social interactions. Normalization processes scale all feature data to a common range, enabling the model to learn more effectively. These preprocessing steps are crucial for enhancing the performance and accuracy of the BPNN model.
Second, the data flow between the course recommendation, career guidance, and enterprise cooperation systems is bidirectional and dynamically adjusted. Students’ personal information and academic performance data flow from the school management system into the BPNN model, which processes this data to provide course recommendations and career development advice. Additionally, student feedback and enterprise needs are updated back into the model to continually optimize the recommendation algorithms and collaboration projects. The exact role of BPNN in each decision-making step lies in its ability to automatically learn and adjust based on the input feature data to predict the best course matches, career paths, and collaboration opportunities. This predictive capability enables BPNN to independently support decision-making without explicit programming instructions, offering more precise services for students and enterprises.
link